Want to take part in these discussions? Sign in if you have an account, or apply for one below
Vanilla 1.1.10 is a product of Lussumo. More Information: Documentation, Community Support.
Hi! Corbin here with yet another ridiculous idea.
Quoting from the infamous database of categories discussion:
I remember someone at nLab could write the database in Ruby, is this offer still on?
I want to propose something quite different.
I’ve prototyped what I’m thinking of as a catabase. This is a plain SQL database which encodes some relations between categories, considering them as first-order objects. For example, there is a table called categories with a column for category names, and two human-readable columns describing objects and arrows. There’s a table called subcategories with a column for subcategory names, and a column for parent category names. Indeed, for all properties and structures listed by Baez as “the basic properties one instantly wants to know about any category one meets,” there is a table or view. For example, in the case of finite limits, there is a table categorical_structure which pairs categories with universal objects (and a table universal_objects) and a view has_finite_limits which queries that table to enumerate categories which have sufficient universal objects to have all finite limits.
Further, I have prototyped the basics of user-friendly display using Datasette. For each category, and some categorical structures, a nice blurb is generated. This is similar to the Abstract Wikipedia proposal. For example, the table karoubi_envelopes has formatting so that Datasette prints the following upon viewing a row:
The category Man is the Karoubi envelope of Op(FinCartSp). Put another way, Op(FinCartSp) is a wide subcategory of Man and every idempotent in Man is split.
While terse (and probably wrong, as I’m not actually good at maths!) this is well-formatted and can be arbitrarily extended with basic SQL and HTML knowledge.
It’s not at all perfect. A short summary of issues:
categories table has 25 queries, of which four fit the N+1 antipattern.groupoids is effectively a view on categories, but topoi is its own table, because topoi have some associated properties (whether it has an NNO, is Boolean, etc.) while groupoids are merely categories which satisfy a property. This leads to…categories, or should there be a table 2-categories? Or more pointedly, every core is an essentially wide subcategory, but some cores are only known as special cases; how should the tables cores and essentially_wide_subcategories be factored?
categorical_structure for all universal properties, and a table enrichments for al enriched categories; they could be finer-grained.How could this be productionized? The main concern is multiple writers to a single source of truth, and so I imagine that SQLite would be replaced with Pg. Otherwise, though, I’m not sure that it’d be different from any other Datasette deployment; there’s a Docker image, a database that has to be backed up, and a list of contributor keys to authenticate writers.
What would be better? Wagn (now Decko) is pretty nifty, although it used to be a headache to administer and I’m not sure whether it’s gotten easier.
Thanks for reading! I am extremely interested in folks’ feelings about this.
~ C.
A prototype instance is now published here, on the free tier of Fly.
I forget if we two spoke about this:
I’ll caution against going further ahead with this without having some real use-case to aim at.
There are just too many categories. Tabulating them without further constraints is worse than tabulating grains of sand in Ar Rub’ al Khali.
Cases where I can see that a “database” might have a use are narrow fields of mathematics that use a zoo of similar but different categories in their foundations:
One good example is the diagram of categories of topological vectors spaces here. A partial database of categories could be useful if it could usefully expand on this diagram.
A similar web of categories exists for variants of plain topological spaces, and here people do go and want to look up thinks like which quotients are preserved in which one, and the like.
These two might be good test cases to aim at, since they are comapratively basic while already of actual interest to working mathematicians.
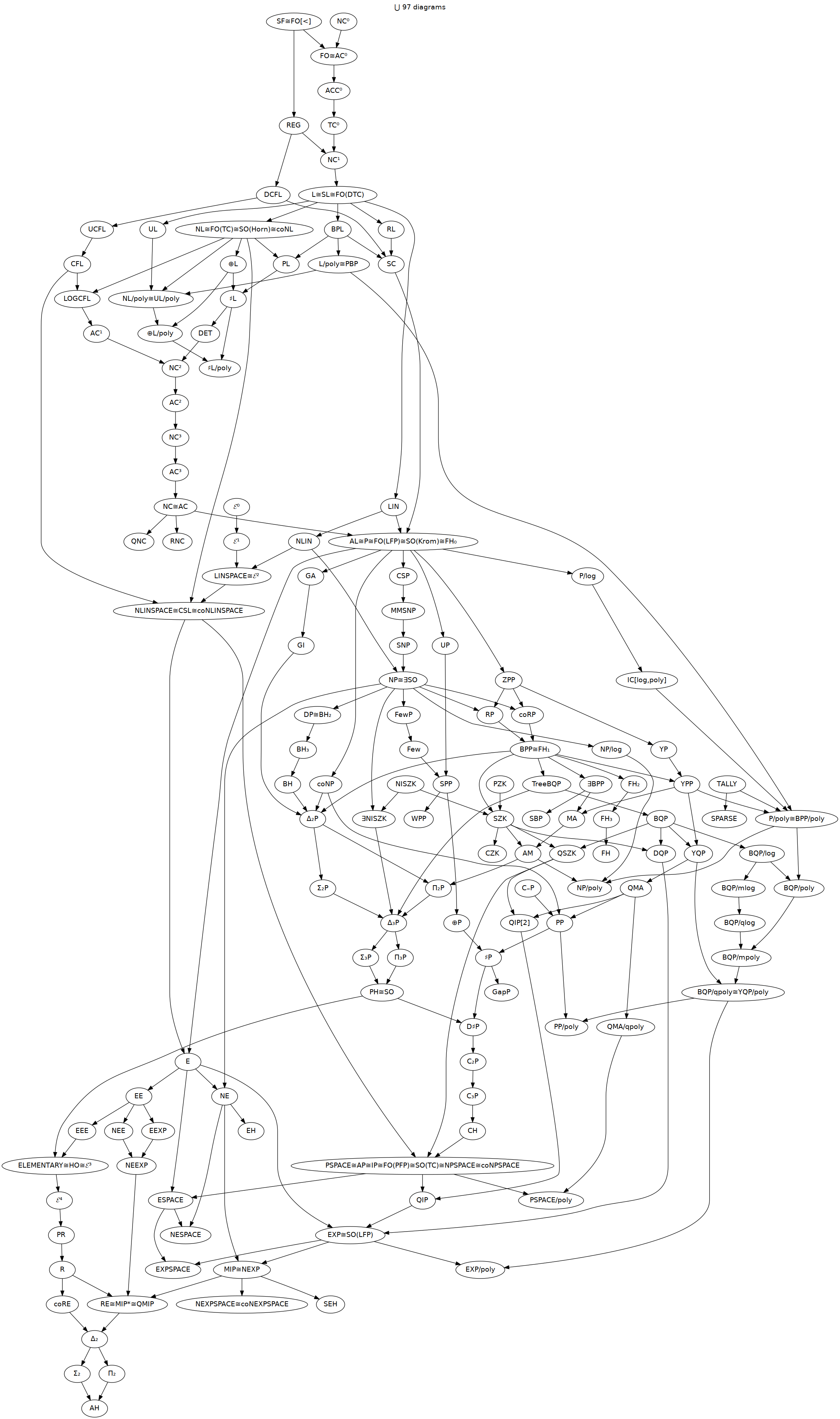
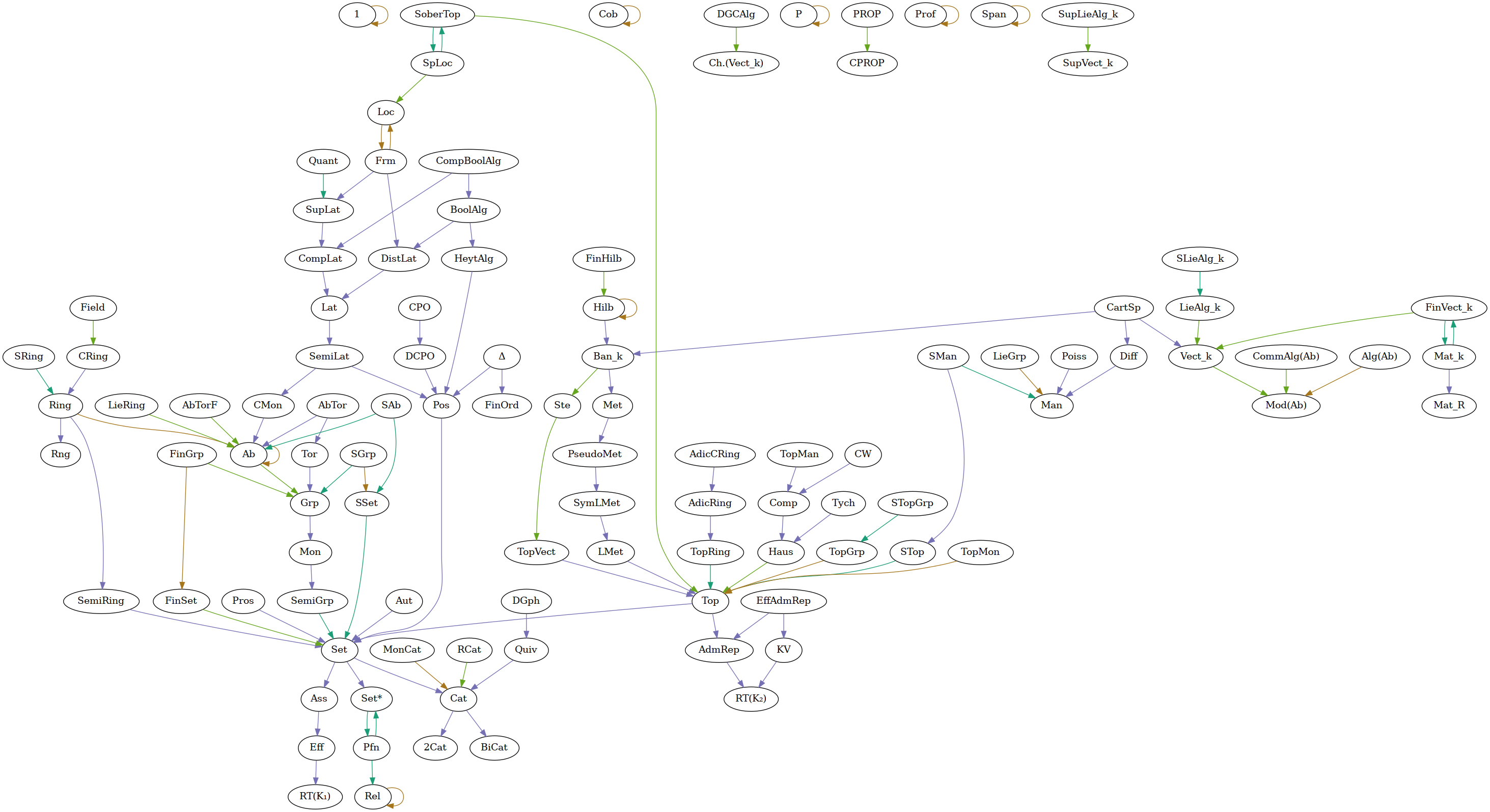
Ah, no worries! I don’t think we’ve chatted before. Hi, I’m Corbin; I’m an independent computer scientist. (Technically, a musician, but same thing.) Like Greg, I like drawing pictures; I wrote a tool called zaha to help me draw diagrams like big.png. (This link is indeterminate, but right now it points to a picture of complexity classes, another area where Greg has contributed.) Maybe more on-topic, I also used zaha to prepare separation.png, a partial order of the basic axioms of topology.
It’s entirely possible that I’m only doing this in order to have some pretty pictures. Here is subcats.png, made with an (already-checked-in) script which extracts the all_subcategories view and color-codes each subcategory functor based on whether it is from an equivalence, opposite, full subcategory, etc. I find the subcategory relation fascinating because it is not strictly about size, cardinality, or measurement, but is still a preorder.
It’s also entirely possible that I’m only doing this as a prototype of how to create a sort of “Abstract nLab”. If you haven’t looked carefully at Abstract Wikipedia (which will launch as Wikifunctions next year), I will summarize it as an attempt to simplify and regularize large portions of Wikipedia by importing data from Wikidata relations into preformatted templates. Or perhaps as a prototype of an nLab which is more like the L-Functions & Modular Forms Database. It is true that there are too many categories to count, but that has not stopped folks from desiring a lower maintenance burden and a more uniform approach to relations between objects.
I guess I should also mention the Complexity Zoo as another place where automated relational reasoning could help. (I’ve checked in a complexity.db but it is still minimal compared to what’s in zaha right now.) However, the so-called “relativization barrier” tells us that the central question of complexity theory, the relationship between P and NP, cannot be determined simply by using basic lattice operations, and it can be shown that relational algebra is limited to those operations. In this field, at least, we know for sure that a database would not make progress compared to other avenues of research.
I wrote a tool called zaha to help me draw diagrams like big.png. (This link is indeterminate, but right now it points to a picture of complexity classes, another area where Greg has contributed.) Maybe more on-topic, I also used zaha to prepare separation.png, a partial order of the basic axioms of topology.
Thanks for these pointers! Ah, so I see that you are way further ahead than I previously got the impression. This looks really useful. This is right along the lines of that graph of categories of topological vector spaces that I thought would be a good example to aim at.
I also like the example separation.png. This would be great to include at separation axiom!
Could this be made into a hyperlinked gadget that would take the reader to corresponding nLab pages? E.g. such that clicking on “T2” would take the reader to the entry Hausdorff space, etc.?
I see that you are ready to contribute. Let me know if you need help with how to include your diagrams. The way to go is a tad convoluted, but not too bad:
First open the Sandbox and type something like
[[SeparationAxiomsPoset-211007.jpg:file]]
Then “submit” the code.
Then find a grayish link saying “SeparationAxiomsPoset-211007.jpg”.
Then click on it.
Then follow the upload dialogue.
Then your file is sitting at
https://ncatlab.org/nlab/files/SeparationAxiomsPoset-211007.jpg
The image could be included from there with usual HTML syntax. But preferred is the following house style syntax:
Go to the entry separation axiom (or the like) and give it something like the following lines:
\begin{imagefromfile}
"file_name": "SeparationAxiomsPoset-211007.jpg",
"width": 600,
"unit": "px",
"margin": {
"top": -40,
"bottom": 20,
"right": 0,
"left": 10
},
"caption": "From [github.com/MostAwesomeDude/zaha](#https://github.com/MostAwesomeDude/zaha)"
\end{imagefromfile}
1 to 6 of 6
{kind=link}
{kind=link}
{kind=link}